CT Training and Reconstructions with UNet#
This example demonstrates the training and application of UNet to denoise previously filtered back projections (FBP) for CT reconstruction inspired by [29].
[1]:
import os
from time import time
import jax
from mpl_toolkits.axes_grid1 import make_axes_locatable
from scico import flax as sflax
from scico import metric, plot
from scico.flax.examples import load_ct_data
plot.config_notebook_plotting()
Prepare parallel processing. Set an arbitrary processor count (only applies if GPU is not available).
[2]:
os.environ["XLA_FLAGS"] = "--xla_force_host_platform_device_count=8"
platform = jax.lib.xla_bridge.get_backend().platform
print("Platform: ", platform)
Platform: gpu
Read data from cache or generate if not available.
[3]:
N = 256 # phantom size
train_nimg = 498 # number of training images
test_nimg = 32 # number of testing images
nimg = train_nimg + test_nimg
n_projection = 45 # CT views
trdt, ttdt = load_ct_data(train_nimg, test_nimg, N, n_projection, verbose=True)
Data read from path : ~/.cache/scico/examples/data
Set --training-- : Size: 498
Set --testing -- : Size: 32
Data range --images -- : Min: 0.00, Max: 1.00
Data range --sinogram-- : Min: 0.00, Max: 0.67
Data range --FBP -- : Min: 0.00, Max: 1.00
Build training and testing structures. Inputs are the filter back-projected sinograms and outpus are the original generated foams. Keep training and testing partitions.
[4]:
train_ds = {"image": trdt["fbp"], "label": trdt["img"]}
test_ds = {"image": ttdt["fbp"], "label": ttdt["img"]}
Define configuration dictionary for model and training loop.
Parameters have been selected for demonstration purposes and relatively short training. The model depth controls the levels of pooling in the U-Net model. The block depth controls the number of layers at each level of depth. The number of filters controls the number of filters at the input and output levels and doubles (halves) at each pooling (unpooling) operation. Better performance may be obtained by increasing depth, block depth, number of filters or training epochs, but may require longer training times.
[5]:
# model configuration
model_conf = {
"depth": 2,
"num_filters": 64,
"block_depth": 2,
}
# training configuration
train_conf: sflax.ConfigDict = {
"seed": 0,
"opt_type": "SGD",
"momentum": 0.9,
"batch_size": 16,
"num_epochs": 200,
"base_learning_rate": 1e-2,
"warmup_epochs": 0,
"log_every_steps": 1000,
"log": True,
"checkpointing": True,
}
Construct UNet model.
[6]:
channels = train_ds["image"].shape[-1]
model = sflax.UNet(
depth=model_conf["depth"],
channels=channels,
num_filters=model_conf["num_filters"],
block_depth=model_conf["block_depth"],
)
Run training loop.
[7]:
workdir = os.path.join(os.path.expanduser("~"), ".cache", "scico", "examples", "unet_ct_out")
train_conf["workdir"] = workdir
print(f"{'JAX process: '}{jax.process_index()}{' / '}{jax.process_count()}")
print(f"{'JAX local devices: '}{jax.local_devices()}")
# Construct training object
trainer = sflax.BasicFlaxTrainer(
train_conf,
model,
train_ds,
test_ds,
)
start_time = time()
modvar, stats_object = trainer.train()
time_train = time() - start_time
JAX process: 0 / 1
JAX local devices: [cuda(id=0), cuda(id=1), cuda(id=2), cuda(id=3), cuda(id=4), cuda(id=5), cuda(id=6), cuda(id=7)]
Channels: 1, training signals: 498, testing signals: 32, signal size: 256
+----------------------------------------------------+------------------+---------+-----------+--------+
| Name | Shape | Size | Mean | Std |
+----------------------------------------------------+------------------+---------+-----------+--------+
| ConvBNMultiBlock_0/ConvBNBlock_0/BatchNorm_0/bias | (64,) | 64 | 0.0 | 0.0 |
| ConvBNMultiBlock_0/ConvBNBlock_0/BatchNorm_0/scale | (64,) | 64 | 1.0 | 0.0 |
| ConvBNMultiBlock_0/ConvBNBlock_0/Conv_0/kernel | (3, 3, 1, 64) | 576 | 0.00194 | 0.488 |
| ConvBNMultiBlock_0/ConvBNBlock_1/BatchNorm_0/bias | (64,) | 64 | 0.0 | 0.0 |
| ConvBNMultiBlock_0/ConvBNBlock_1/BatchNorm_0/scale | (64,) | 64 | 1.0 | 0.0 |
| ConvBNMultiBlock_0/ConvBNBlock_1/Conv_0/kernel | (3, 3, 64, 64) | 36,864 | -0.00022 | 0.0588 |
| ConvBNMultiBlock_1/ConvBNBlock_0/BatchNorm_0/bias | (128,) | 128 | 0.0 | 0.0 |
| ConvBNMultiBlock_1/ConvBNBlock_0/BatchNorm_0/scale | (128,) | 128 | 1.0 | 0.0 |
| ConvBNMultiBlock_1/ConvBNBlock_0/Conv_0/kernel | (3, 3, 128, 128) | 147,456 | -1.14e-07 | 0.0417 |
| ConvBNMultiBlock_1/ConvBNBlock_1/BatchNorm_0/bias | (128,) | 128 | 0.0 | 0.0 |
| ConvBNMultiBlock_1/ConvBNBlock_1/BatchNorm_0/scale | (128,) | 128 | 1.0 | 0.0 |
| ConvBNMultiBlock_1/ConvBNBlock_1/Conv_0/kernel | (3, 3, 128, 128) | 147,456 | -0.000212 | 0.0417 |
| ConvBNMultiBlock_2/ConvBNBlock_0/BatchNorm_0/bias | (64,) | 64 | 0.0 | 0.0 |
| ConvBNMultiBlock_2/ConvBNBlock_0/BatchNorm_0/scale | (64,) | 64 | 1.0 | 0.0 |
| ConvBNMultiBlock_2/ConvBNBlock_0/Conv_0/kernel | (3, 3, 128, 64) | 73,728 | 0.000144 | 0.0417 |
| ConvBNMultiBlock_2/ConvBNBlock_1/BatchNorm_0/bias | (64,) | 64 | 0.0 | 0.0 |
| ConvBNMultiBlock_2/ConvBNBlock_1/BatchNorm_0/scale | (64,) | 64 | 1.0 | 0.0 |
| ConvBNMultiBlock_2/ConvBNBlock_1/Conv_0/kernel | (3, 3, 64, 64) | 36,864 | -0.000357 | 0.0591 |
| ConvBNPoolBlock_0/BatchNorm_0/bias | (128,) | 128 | 0.0 | 0.0 |
| ConvBNPoolBlock_0/BatchNorm_0/scale | (128,) | 128 | 1.0 | 0.0 |
| ConvBNPoolBlock_0/Conv_0/kernel | (3, 3, 64, 128) | 73,728 | -0.00056 | 0.0588 |
| ConvBNUpsampleBlock_0/BatchNorm_0/bias | (64,) | 64 | 0.0 | 0.0 |
| ConvBNUpsampleBlock_0/BatchNorm_0/scale | (64,) | 64 | 1.0 | 0.0 |
| ConvBNUpsampleBlock_0/Conv_0/kernel | (3, 3, 128, 64) | 73,728 | -9.9e-05 | 0.0418 |
| Conv_0/kernel | (1, 1, 64, 1) | 64 | -0.0134 | 0.184 |
+----------------------------------------------------+------------------+---------+-----------+--------+
Total: 591,872
+---------------------------------------------------+--------+------+------+-----+
| Name | Shape | Size | Mean | Std |
+---------------------------------------------------+--------+------+------+-----+
| ConvBNMultiBlock_0/ConvBNBlock_0/BatchNorm_0/mean | (64,) | 64 | 0.0 | 0.0 |
| ConvBNMultiBlock_0/ConvBNBlock_0/BatchNorm_0/var | (64,) | 64 | 1.0 | 0.0 |
| ConvBNMultiBlock_0/ConvBNBlock_1/BatchNorm_0/mean | (64,) | 64 | 0.0 | 0.0 |
| ConvBNMultiBlock_0/ConvBNBlock_1/BatchNorm_0/var | (64,) | 64 | 1.0 | 0.0 |
| ConvBNMultiBlock_1/ConvBNBlock_0/BatchNorm_0/mean | (128,) | 128 | 0.0 | 0.0 |
| ConvBNMultiBlock_1/ConvBNBlock_0/BatchNorm_0/var | (128,) | 128 | 1.0 | 0.0 |
| ConvBNMultiBlock_1/ConvBNBlock_1/BatchNorm_0/mean | (128,) | 128 | 0.0 | 0.0 |
| ConvBNMultiBlock_1/ConvBNBlock_1/BatchNorm_0/var | (128,) | 128 | 1.0 | 0.0 |
| ConvBNMultiBlock_2/ConvBNBlock_0/BatchNorm_0/mean | (64,) | 64 | 0.0 | 0.0 |
| ConvBNMultiBlock_2/ConvBNBlock_0/BatchNorm_0/var | (64,) | 64 | 1.0 | 0.0 |
| ConvBNMultiBlock_2/ConvBNBlock_1/BatchNorm_0/mean | (64,) | 64 | 0.0 | 0.0 |
| ConvBNMultiBlock_2/ConvBNBlock_1/BatchNorm_0/var | (64,) | 64 | 1.0 | 0.0 |
| ConvBNPoolBlock_0/BatchNorm_0/mean | (128,) | 128 | 0.0 | 0.0 |
| ConvBNPoolBlock_0/BatchNorm_0/var | (128,) | 128 | 1.0 | 0.0 |
| ConvBNUpsampleBlock_0/BatchNorm_0/mean | (64,) | 64 | 0.0 | 0.0 |
| ConvBNUpsampleBlock_0/BatchNorm_0/var | (64,) | 64 | 1.0 | 0.0 |
+---------------------------------------------------+--------+------+------+-----+
Total: 1,408
Initial compilation, this might take some minutes...
2023-11-14 18:02:24.906244: W external/tsl/tsl/framework/bfc_allocator.cc:296] Allocator (GPU_0_bfc) ran out of memory trying to allocate 8.20GiB with freed_by_count=0. The caller indicates that this is not a failure, but this may mean that there could be performance gains if more memory were available.
2023-11-14 18:02:24.988230: W external/tsl/tsl/framework/bfc_allocator.cc:296] Allocator (GPU_0_bfc) ran out of memory trying to allocate 8.20GiB with freed_by_count=0. The caller indicates that this is not a failure, but this may mean that there could be performance gains if more memory were available.
2023-11-14 18:02:26.853697: W external/tsl/tsl/framework/bfc_allocator.cc:296] Allocator (GPU_0_bfc) ran out of memory trying to allocate 8.20GiB with freed_by_count=0. The caller indicates that this is not a failure, but this may mean that there could be performance gains if more memory were available.
2023-11-14 18:02:26.912393: W external/tsl/tsl/framework/bfc_allocator.cc:296] Allocator (GPU_0_bfc) ran out of memory trying to allocate 8.20GiB with freed_by_count=0. The caller indicates that this is not a failure, but this may mean that there could be performance gains if more memory were available.
2023-11-14 18:02:27.524788: W external/tsl/tsl/framework/bfc_allocator.cc:296] Allocator (GPU_0_bfc) ran out of memory trying to allocate 8.09GiB with freed_by_count=0. The caller indicates that this is not a failure, but this may mean that there could be performance gains if more memory were available.
2023-11-14 18:02:27.591727: W external/tsl/tsl/framework/bfc_allocator.cc:296] Allocator (GPU_0_bfc) ran out of memory trying to allocate 8.09GiB with freed_by_count=0. The caller indicates that this is not a failure, but this may mean that there could be performance gains if more memory were available.
Initial compilation completed.
Epoch Time Train_LR Train_Loss Train_SNR Eval_Loss Eval_SNR
---------------------------------------------------------------------
32 4.67e+01 0.010000 0.012132 7.38 0.006161 8.71
64 8.34e+01 0.010000 0.005826 8.97 0.005428 9.26
96 1.20e+02 0.010000 0.005360 9.33 0.005107 9.53
129 1.56e+02 0.010000 0.005114 9.54 0.004915 9.69
161 1.93e+02 0.010000 0.004956 9.67 0.004785 9.81
193 2.30e+02 0.010000 0.004843 9.77 0.004693 9.90
Evaluate on testing data.
[8]:
del train_ds["image"]
del train_ds["label"]
fmap = sflax.FlaxMap(model, modvar)
del model, modvar
maxn = test_nimg // 2
start_time = time()
output = fmap(test_ds["image"][:maxn])
time_eval = time() - start_time
output = jax.numpy.clip(output, a_min=0, a_max=1.0)
2023-11-14 18:06:27.103274: W external/tsl/tsl/framework/bfc_allocator.cc:296] Allocator (GPU_0_bfc) ran out of memory trying to allocate 9.09GiB with freed_by_count=0. The caller indicates that this is not a failure, but this may mean that there could be performance gains if more memory were available.
2023-11-14 18:06:27.588965: W external/tsl/tsl/framework/bfc_allocator.cc:296] Allocator (GPU_0_bfc) ran out of memory trying to allocate 9.09GiB with freed_by_count=0. The caller indicates that this is not a failure, but this may mean that there could be performance gains if more memory were available.
2023-11-14 18:06:31.024888: W external/tsl/tsl/framework/bfc_allocator.cc:296] Allocator (GPU_0_bfc) ran out of memory trying to allocate 4.52GiB with freed_by_count=0. The caller indicates that this is not a failure, but this may mean that there could be performance gains if more memory were available.
2023-11-14 18:06:32.049670: W external/tsl/tsl/framework/bfc_allocator.cc:296] Allocator (GPU_0_bfc) ran out of memory trying to allocate 4.52GiB with freed_by_count=0. The caller indicates that this is not a failure, but this may mean that there could be performance gains if more memory were available.
Evaluate trained model in terms of reconstruction time and data fidelity.
[9]:
snr_eval = metric.snr(test_ds["label"][:maxn], output)
psnr_eval = metric.psnr(test_ds["label"][:maxn], output)
print(
f"{'UNet training':15s}{'epochs:':2s}{train_conf['num_epochs']:>5d}"
f"{'':21s}{'time[s]:':10s}{time_train:>7.2f}"
)
print(
f"{'UNet testing':15s}{'SNR:':5s}{snr_eval:>5.2f}{' dB'}{'':3s}"
f"{'PSNR:':6s}{psnr_eval:>5.2f}{' dB'}{'':3s}{'time[s]:':10s}{time_eval:>7.2f}"
)
UNet training epochs: 200 time[s]: 238.18
UNet testing SNR: 10.01 dB PSNR: 20.39 dB time[s]: 12.28
Plot comparison.
[10]:
key = jax.random.PRNGKey(123)
indx = jax.random.randint(key, shape=(1,), minval=0, maxval=test_nimg)[0]
fig, ax = plot.subplots(nrows=1, ncols=3, figsize=(15, 5))
plot.imview(test_ds["label"][indx, ..., 0], title="Ground truth", cbar=None, fig=fig, ax=ax[0])
plot.imview(
test_ds["image"][indx, ..., 0],
title="FBP Reconstruction: \nSNR: %.2f (dB), MAE: %.3f"
% (
metric.snr(test_ds["label"][indx, ..., 0], test_ds["image"][indx, ..., 0]),
metric.mae(test_ds["label"][indx, ..., 0], test_ds["image"][indx, ..., 0]),
),
cbar=None,
fig=fig,
ax=ax[1],
)
plot.imview(
output[indx, ..., 0],
title="UNet Reconstruction\nSNR: %.2f (dB), MAE: %.3f"
% (
metric.snr(test_ds["label"][indx, ..., 0], output[indx, ..., 0]),
metric.mae(test_ds["label"][indx, ..., 0], output[indx, ..., 0]),
),
fig=fig,
ax=ax[2],
)
divider = make_axes_locatable(ax[2])
cax = divider.append_axes("right", size="5%", pad=0.2)
fig.colorbar(ax[2].get_images()[0], cax=cax, label="arbitrary units")
fig.show()

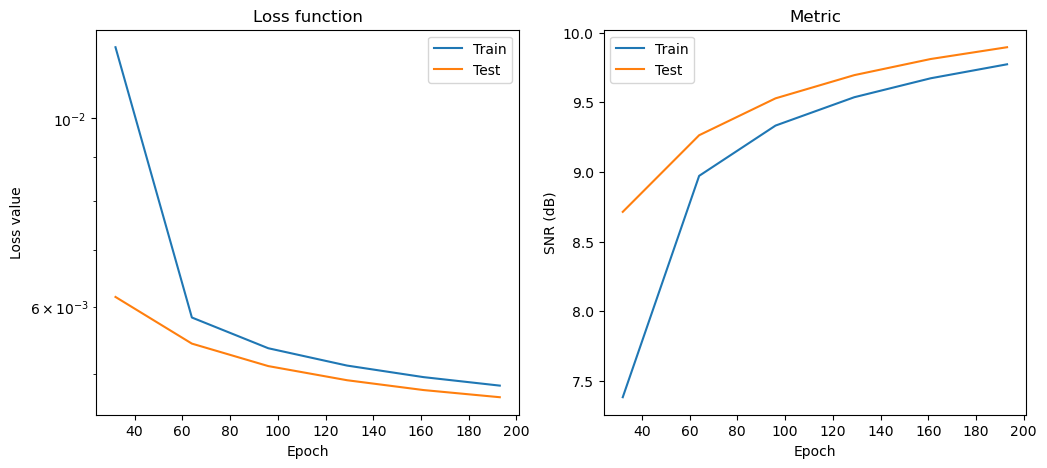
Plot convergence statistics. Statistics are generated only if a training cycle was done (i.e. if not reading final epoch results from checkpoint).
[11]:
if stats_object is not None and len(stats_object.iterations) > 0:
hist = stats_object.history(transpose=True)
fig, ax = plot.subplots(nrows=1, ncols=2, figsize=(12, 5))
plot.plot(
jax.numpy.vstack((hist.Train_Loss, hist.Eval_Loss)).T,
x=hist.Epoch,
ptyp="semilogy",
title="Loss function",
xlbl="Epoch",
ylbl="Loss value",
lgnd=("Train", "Test"),
fig=fig,
ax=ax[0],
)
plot.plot(
jax.numpy.vstack((hist.Train_SNR, hist.Eval_SNR)).T,
x=hist.Epoch,
title="Metric",
xlbl="Epoch",
ylbl="SNR (dB)",
lgnd=("Train", "Test"),
fig=fig,
ax=ax[1],
)
fig.show()
/tmp/ipykernel_183781/164368498.py:5: DeprecationWarning: vstack requires ndarray or scalar arguments, got <class 'list'> at position 0.In a future JAX release this will be an error.
jax.numpy.vstack((hist.Train_Loss, hist.Eval_Loss)).T,
/tmp/ipykernel_183781/164368498.py:16: DeprecationWarning: vstack requires ndarray or scalar arguments, got <class 'list'> at position 0.In a future JAX release this will be an error.
jax.numpy.vstack((hist.Train_SNR, hist.Eval_SNR)).T,