scico.linop¶
Linear operator functions and classes.
Modules
Optical propagator classes. |
|
X-ray transform classes. |
Functions
|
Construct Jacobian linear operator for a general operator. |
|
Make a |
|
Construct a list of |
|
Estimate the norm of a |
|
Compute largest eigenvalue of a diagonalizable |
|
Check whether |
Classes
|
A circular convolution linear operator. |
|
A composition of two |
|
A convolution linear operator. |
|
A linear operator for cropping an array. |
|
Gradient projected into cylindrical coordinates. |
|
Multi-dimensional discrete Fourier transform. |
|
Diagonal linear operator. |
|
A diagonal stack constructed from a single linear operator. |
|
A diagonal stack of linear operators. |
|
Finite difference operator. |
|
Identity operator. |
|
Generic linear operator base class |
|
Linear operator implementing matrix multiplication. |
|
Linear operator version of |
|
Gradient projected into polar coordinates. |
|
Gradient projected onto local coordinate system. |
|
Linear operator version of |
|
Scaled identity operator. |
|
Finite difference operator acting along a single axis. |
|
A linear operator for slicing an array. |
|
Gradient projected into spherical coordinates. |
|
Linear operator version of |
|
Linear operator version of |
|
A vertical stack of linear operators. |
- class scico.linop.CircularConvolve(h, input_shape, ndims=None, input_dtype=<class 'jax.numpy.float32'>, h_is_dft=False, h_center=None, jit=True, **kwargs)¶
Bases:
LinearOperatorA circular convolution linear operator.
This linear operator implements circular, multi-dimensional convolution via pointwise multiplication in the DFT domain. In its simplest form, it implements a single convolution and can be represented by linear operator \(H\) such that
\[H \mb{x} = \mb{h} \ast \mb{x} \;,\]where \(\mb{h}\) is a user-defined filter.
More complex forms, corresponding to the case where either the input (as represented by parameter input_shape) or filter (parameter h) have additional axes that are not involved in the convolution are also supported. These follow numpy broadcasting rules. For example:
Additional axes in the input \(\mb{x}\) and not in \(\mb{h}\) corresponds to the operation
\[\begin{split}H \mb{x} = \left( \begin{array}{ccc} H' & 0 & \ldots\\ 0 & H' & \ldots\\ \vdots & \vdots & \ddots \end{array} \right) \left( \begin{array}{c} \mb{x}_0\\ \mb{x}_1\\ \vdots \end{array} \right) \;.\end{split}\]Additional axes in \(\mb{h}\) corresponds to multiple filters, which will be denoted by \(\{\mb{h}_m\}\), with corresponding individual linear operations being denoted by \(h_m \mb{x}_m = \mb{h}_m \ast \mb{x}_m\). The full linear operator can then be represented as
\[\begin{split}H \mb{x} = \left( \begin{array}{c} H_0\\ H_1\\ \vdots \end{array} \right) \mb{x} \;.\end{split}\]if the input is singleton, and as
\[\begin{split}H \mb{x} = \left( \begin{array}{ccc} H_0 & 0 & \ldots\\ 0 & H_1 & \ldots\\ \vdots & \vdots & \ddots \end{array} \right) \left( \begin{array}{c} \mb{x}_0\\ \mb{x}_1\\ \vdots \end{array} \right)\end{split}\]otherwise.
- Parameters:
h (
Array) – Array of filters.ndims (
Optional[int]) – Number of (trailing) dimensions of the input and h involved in the convolution. Defaults to the number of dimensions in the input.input_dtype (
DType) – dtype for input argument. Defaults tofloat32.h_is_dft (
bool) – Flag indicating whether h is in the DFT domain.h_center (
Union[Array,ndarray,Sequence,float,int,None]) – Array of length ndims specifying the center of the filter. Defaults to the upper left corner, i.e., h_center = [0, 0, …, 0], may be noninteger. May be afloatorintif h is one-dimensional.jit (
bool) – IfTrue, jit the evaluation, adjoint, and gram functions of theLinearOperator.
- static from_operator(H, ndims=None, center=None, jit=True)[source]¶
Construct a CircularConvolve version of a given operator.
Construct a CircularConvolve version of a given operator, which is assumed to be linear and shift invariant (LSI).
- Parameters:
H (
Operator) – Input operator.ndims (
Optional[int]) – Number of trailing dims over which the H acts.center (
Optional[Tuple[int,...]]) – Location at which to place the Kronecker delta. For LSI inputs, this will not matter. Defaults to the center of H.input_shape, i.e., (n_1 // 2, n_2 // 2, …).jit (
bool) – IfTrue, jit the resulting CircularConvolve.
- class scico.linop.Convolve(h, input_shape, input_dtype=<class 'numpy.float32'>, mode='full', jit=True, **kwargs)¶
Bases:
LinearOperatorA convolution linear operator.
Wrap
jax.scipy.signal.convolveas aLinearOperator.- Parameters:
h (
Array) – Convolutional filter. Must have same number of dimensions as len(input_shape).input_dtype (
DType) – dtype for input argument. Defaults tofloat32.mode (
str) – A string indicating the size of the output. One of “full”, “valid”, “same”. Defaults to “full”.jit (
bool) – IfTrue, jit the evaluation, adjoint, and gram functions of theLinearOperator.
For more details on mode, see
jax.scipy.signal.convolve.
- class scico.linop.DFT(input_shape, axes=None, axes_shape=None, norm=None, jit=True, **kwargs)¶
Bases:
LinearOperatorMulti-dimensional discrete Fourier transform.
- Parameters:
axes (
Optional[Sequence]) – Axes over which to compute the DFT. IfNone, the DFT is computed over all axes.axes_shape (
Optional[Tuple[int,...]]) – Output shape on the subset of array axes selected by axes. This parameter has the same behavior as the s parameter ofnumpy.fft.fftn.norm (
Optional[str]) – DFT normalization mode. See the norm parameter ofnumpy.fft.fftn.jit (
bool) – IfTrue, jit the evaluation, adjoint, and gram functions of the LinearOperator.
- class scico.linop.Diagonal(diagonal, input_shape=None, input_dtype=None, **kwargs)¶
Bases:
LinearOperatorDiagonal linear operator.
- Parameters:
diagonal (
Union[Array,BlockArray]) – Diagonal elements of thisLinearOperator.input_shape (
Union[Tuple[int,...],Tuple[Tuple[int,...],...],None]) – Shape of input array. By default, equal to diagonal.shape, but may also be set to a shape that is broadcast-compatible with diagonal.shape.input_dtype (
Optional[DType]) – dtype of input argument. The default,None, means diagonal.dtype.
- property diagonal: Array | BlockArray¶
Return an array representing the diagonal component.
- property gram_op: Diagonal¶
Gram operator of this
Diagonal.Return a new
DiagonalGsuch thatG(x) = A.adj(A(x))).
- norm(ord=None)[source]¶
Compute the matrix norm of the diagonal operator.
Valid values of ord and the corresponding norm definition are those listed under “norm for matrices” in the
scico.numpy.linalg.normdocumentation.
- class scico.linop.Identity(input_shape, input_dtype=<class 'jax.numpy.float32'>, **kwargs)¶
Bases:
ScaledIdentityIdentity operator.
- Parameters:
- class scico.linop.ScaledIdentity(scalar, input_shape, input_dtype=<class 'jax.numpy.float32'>, **kwargs)¶
Bases:
DiagonalScaled identity operator.
- Parameters:
- conj()[source]¶
Complex conjugate of this
ScaledIdentity.- Return type:
- property diagonal: Array | BlockArray¶
Return an array representing the diagonal component.
- property gram_op: ScaledIdentity¶
Gram operator of this
ScaledIdentity.
- norm(ord=None)[source]¶
Compute the matrix norm of the identity operator.
Valid values of ord and the corresponding norm definition are those listed under “norm for matrices” in the
scico.numpy.linalg.normdocumentation.
- class scico.linop.FiniteDifference(input_shape, input_dtype=<class 'numpy.float32'>, axes=None, prepend=None, append=None, circular=False, jit=True, **kwargs)¶
Bases:
VerticalStackFinite difference operator.
Compute finite differences along the specified axes, returning the results in a
jax.Array(when possible) orBlockArray. SeeVerticalStackfor details on how this choice is made. SeeSingleAxisFiniteDifferencefor the mathematical implications of the different boundary handling options prepend, append, and circular.Example
>>> A = FiniteDifference((2, 3)) >>> x = snp.array([[1, 2, 4], ... [0, 4, 1]]) >>> (A @ x)[0] Array([[-1, 2, -3]], dtype=int32) >>> (A @ x)[1] Array([[ 1, 2], [ 4, -3]], dtype=int32)
- Parameters:
input_dtype (
DType) – dtype for input argument. Defaults tofloat32.axes (
Union[int,Tuple[int,...],List[int],None]) – Axis or axes over which to apply finite difference operator. If not specified, orNone, differences are evaluated along all axes.prepend (
Union[Literal[0],Literal[1],None]) – Flag indicating handling of the left/top/etc. boundary. IfNone, there is no boundary extension. Values of 0 or 1 indicate respectively that zeros or the initial value in the array are prepended to the difference array.append (
Union[Literal[0],Literal[1],None]) – Flag indicating handling of the right/bottom/etc. boundary. IfNone, there is no boundary extension. Values of 0 or 1 indicate respectively that zeros or -1 times the final value in the array are appended to the difference array.circular (
bool) – IfTrue, perform circular differences, i.e., include x[-1] - x[0]. IfTrue, prepend and append must both beNone.jit (
bool) – IfTrue, jit the evaluation, adjoint, and gram functions of theLinearOperator.
- class scico.linop.SingleAxisFiniteDifference(input_shape, input_dtype=<class 'numpy.float32'>, axis=-1, prepend=None, append=None, circular=False, jit=True, **kwargs)¶
Bases:
LinearOperatorFinite difference operator acting along a single axis.
By default (i.e. prepend and append set to
Noneand circular set toFalse), the difference operator corresponds to the matrix\[\begin{split}\left(\begin{array}{rrrrr} -1 & 1 & 0 & \ldots & 0\\ 0 & -1 & 1 & \ldots & 0\\ \vdots & \vdots & \ddots & \ddots & \vdots\\ 0 & 0 & \ldots & -1 & 1 \end{array}\right) \;,\end{split}\]mapping \(\mbb{R}^N \rightarrow \mbb{R}^{N-1}\), while if circular is
True, it corresponds to the \(\mbb{R}^N \rightarrow \mbb{R}^N\) mapping\[\begin{split}\left(\begin{array}{rrrrr} -1 & 1 & 0 & \ldots & 0\\ 0 & -1 & 1 & \ldots & 0\\ \vdots & \vdots & \ddots & \ddots & \vdots\\ 0 & 0 & \ldots & -1 & 1\\ 1 & 0 & \dots & 0 & -1 \end{array}\right) \;.\end{split}\]Other possible choices include prepend set to
Noneand append set to 0, giving the \(\mbb{R}^N \rightarrow \mbb{R}^N\) mapping\[\begin{split}\left(\begin{array}{rrrrr} -1 & 1 & 0 & \ldots & 0\\ 0 & -1 & 1 & \ldots & 0\\ \vdots & \vdots & \ddots & \ddots & \vdots\\ 0 & 0 & \ldots & -1 & 1\\ 0 & 0 & \dots & 0 & 0 \end{array}\right) \;,\end{split}\]and both prepend and append set to 1, giving the \(\mbb{R}^N \rightarrow \mbb{R}^{N+1}\) mapping
\[\begin{split}\left(\begin{array}{rrrrr} 1 & 0 & 0 & \ldots & 0\\ -1 & 1 & 0 & \ldots & 0\\ 0 & -1 & 1 & \ldots & 0\\ \vdots & \vdots & \ddots & \ddots & \vdots\\ 0 & 0 & \ldots & -1 & 1\\ 0 & 0 & \dots & 0 & -1 \end{array}\right) \;.\end{split}\]- Parameters:
input_dtype (
DType) – dtype for input argument. Defaults tofloat32.axis (
int) – Axis over which to apply finite difference operator.prepend (
Union[Literal[0],Literal[1],None]) – Flag indicating handling of the left/top/etc. boundary. IfNone, there is no boundary extension. Values of 0 or 1 indicate respectively that zeros or the initial value in the array are prepended to the difference array.append (
Union[Literal[0],Literal[1],None]) – Flag indicating handling of the right/bottom/etc. boundary. IfNone, there is no boundary extension. Values of 0 or 1 indicate respectively that zeros or -1 times the final value in the array are appended to the difference array.circular (
bool) – IfTrue, perform circular differences, i.e., include x[-1] - x[0]. IfTrue, prepend and append must both beNone.jit (
bool) – IfTrue, jit the evaluation, adjoint, and gram functions of theLinearOperator.
- class scico.linop.Crop(crop_width, input_shape, input_dtype=<class 'jax.numpy.float32'>, jit=True, **kwargs)¶
Bases:
LinearOperatorA linear operator for cropping an array.
- class scico.linop.Pad(input_shape, *args, input_dtype=<class 'jax.numpy.float32'>, output_shape=None, output_dtype=None, jit=True, **kwargs)¶
Bases:
LinearOperatorLinear operator version of
scico.numpy.pad.- Parameters:
input_shape (
Union[Tuple[int,...],Tuple[Tuple[int,...],...]]) – Shape of input array.args (
Any) – Positional arguments passed toscico.numpy.pad.input_dtype (
DType) – dtype for input argument. Defaults tofloat32. If theLinearOperatorimplements complex-valued operations, this must be a complex dtype (typicallycomplex64) for correct adjoint and gradient calculation.output_shape (
Union[Tuple[int,...],Tuple[Tuple[int,...],...],None]) – Shape of output array. Defaults toNone. IfNone, output_shape is determined by evaluating self.__call__ on an input array of zeros.output_dtype (
Optional[DType]) – dtype for output argument. Defaults toNone. IfNone, output_dtype is determined by evaluating self.__call__ on an input array of zeros.jit (
bool) – IfTrue, calljiton thisLinearOperatorto jit the forward, adjoint, and gram functions. Same as callingjitafter theLinearOperatoris created.kwargs (
Any) – Keyword arguments passed toscico.numpy.pad.
- class scico.linop.Reshape(input_shape, *args, input_dtype=<class 'jax.numpy.float32'>, output_shape=None, output_dtype=None, jit=True, **kwargs)¶
Bases:
LinearOperatorLinear operator version of
scico.numpy.reshape.- Parameters:
input_shape (
Union[Tuple[int,...],Tuple[Tuple[int,...],...]]) – Shape of input array.args (
Any) – Positional arguments passed toscico.numpy.reshape.input_dtype (
DType) – dtype for input argument. Defaults tofloat32. If theLinearOperatorimplements complex-valued operations, this must be a complex dtype (typicallycomplex64) for correct adjoint and gradient calculation.output_shape (
Union[Tuple[int,...],Tuple[Tuple[int,...],...],None]) – Shape of output array. Defaults toNone. IfNone, output_shape is determined by evaluating self.__call__ on an input array of zeros.output_dtype (
Optional[DType]) – dtype for output argument. Defaults toNone. IfNone, output_dtype is determined by evaluating self.__call__ on an input array of zeros.jit (
bool) – IfTrue, calljiton thisLinearOperatorto jit the forward, adjoint, and gram functions. Same as callingjitafter theLinearOperatoris created.kwargs (
Any) – Keyword arguments passed toscico.numpy.reshape.
- class scico.linop.Slice(idx, input_shape, input_dtype=<class 'jax.numpy.float32'>, jit=True, **kwargs)¶
Bases:
LinearOperatorA linear operator for slicing an array.
This operator may be applied to either a
jax.Arrayor aBlockArray. In the latter case, parameter idx must conform to the BlockArray indexing requirements.- Parameters:
idx (
ArrayIndex) – An array indexing expression, as generated bynumpy.s_, for example.input_shape (
Union[Tuple[int,...],Tuple[Tuple[int,...],...]]) – Shape of inputjax.ArrayorBlockArray.input_dtype (
DType) – dtype for input argument. Defaults tofloat32.jit (
bool) – IfTrue, jit the evaluation, adjoint, and gram functions of theLinearOperator.
- class scico.linop.Sum(input_shape, *args, input_dtype=<class 'jax.numpy.float32'>, output_shape=None, output_dtype=None, jit=True, **kwargs)¶
Bases:
LinearOperatorLinear operator version of
scico.numpy.sum.- Parameters:
input_shape (
Union[Tuple[int,...],Tuple[Tuple[int,...],...]]) – Shape of input array.args (
Any) – Positional arguments passed toscico.numpy.sum.input_dtype (
DType) – dtype for input argument. Defaults tofloat32. If theLinearOperatorimplements complex-valued operations, this must be a complex dtype (typicallycomplex64) for correct adjoint and gradient calculation.output_shape (
Union[Tuple[int,...],Tuple[Tuple[int,...],...],None]) – Shape of output array. Defaults toNone. IfNone, output_shape is determined by evaluating self.__call__ on an input array of zeros.output_dtype (
Optional[DType]) – dtype for output argument. Defaults toNone. IfNone, output_dtype is determined by evaluating self.__call__ on an input array of zeros.jit (
bool) – IfTrue, calljiton thisLinearOperatorto jit the forward, adjoint, and gram functions. Same as callingjitafter theLinearOperatoris created.kwargs (
Any) – Keyword arguments passed toscico.numpy.sum.
- class scico.linop.Transpose(input_shape, *args, input_dtype=<class 'jax.numpy.float32'>, output_shape=None, output_dtype=None, jit=True, **kwargs)¶
Bases:
LinearOperatorLinear operator version of
scico.numpy.transpose.- Parameters:
input_shape (
Union[Tuple[int,...],Tuple[Tuple[int,...],...]]) – Shape of input array.args (
Any) – Positional arguments passed toscico.numpy.transpose.input_dtype (
DType) – dtype for input argument. Defaults tofloat32. If theLinearOperatorimplements complex-valued operations, this must be a complex dtype (typicallycomplex64) for correct adjoint and gradient calculation.output_shape (
Union[Tuple[int,...],Tuple[Tuple[int,...],...],None]) – Shape of output array. Defaults toNone. IfNone, output_shape is determined by evaluating self.__call__ on an input array of zeros.output_dtype (
Optional[DType]) – dtype for output argument. Defaults toNone. IfNone, output_dtype is determined by evaluating self.__call__ on an input array of zeros.jit (
bool) – IfTrue, calljiton thisLinearOperatorto jit the forward, adjoint, and gram functions. Same as callingjitafter theLinearOperatoris created.kwargs (
Any) – Keyword arguments passed toscico.numpy.transpose.
- scico.linop.linop_from_function(f, classname, f_name=None)¶
Make a
LinearOperatorfrom a function.Example
>>> Sum = linop_from_function(snp.sum, 'Sum') >>> H = Sum((2, 10), axis=1) >>> H @ snp.ones((2, 10)) Array([10., 10.], dtype=float32)
- Parameters:
f (
Callable) – Function from which to create aLinearOperator.classname (
str) – Name of the resulting class.f_name (
Optional[str]) – Name of f for use in docstrings. Useful for getting the correct version of wrapped functions. Defaults to f”{f.__module__}.{f.__name__}”.
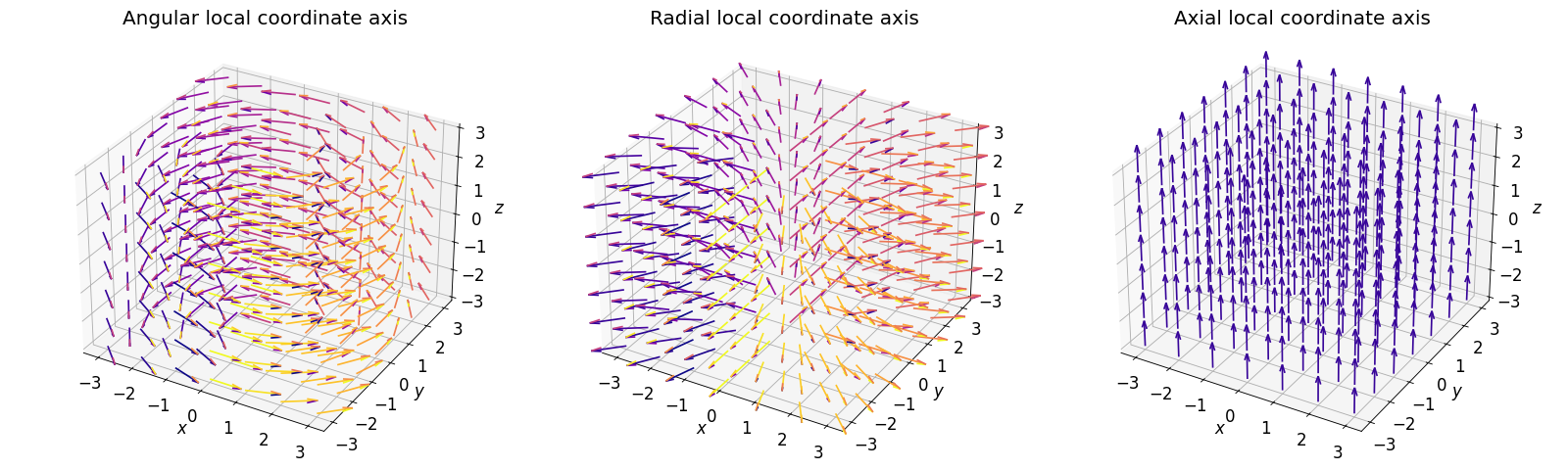
- class scico.linop.CylindricalGradient(input_shape, axes=None, center=None, angular=True, radial=True, axial=True, cdiff=False, input_dtype=<class 'numpy.float32'>, jit=True)¶
Bases:
ProjectedGradientGradient projected into cylindrical coordinates.
Compute gradients projected onto cylindrical coordinate axes, as described in [29]. The local coordinate axes are illustrated in the figure below.
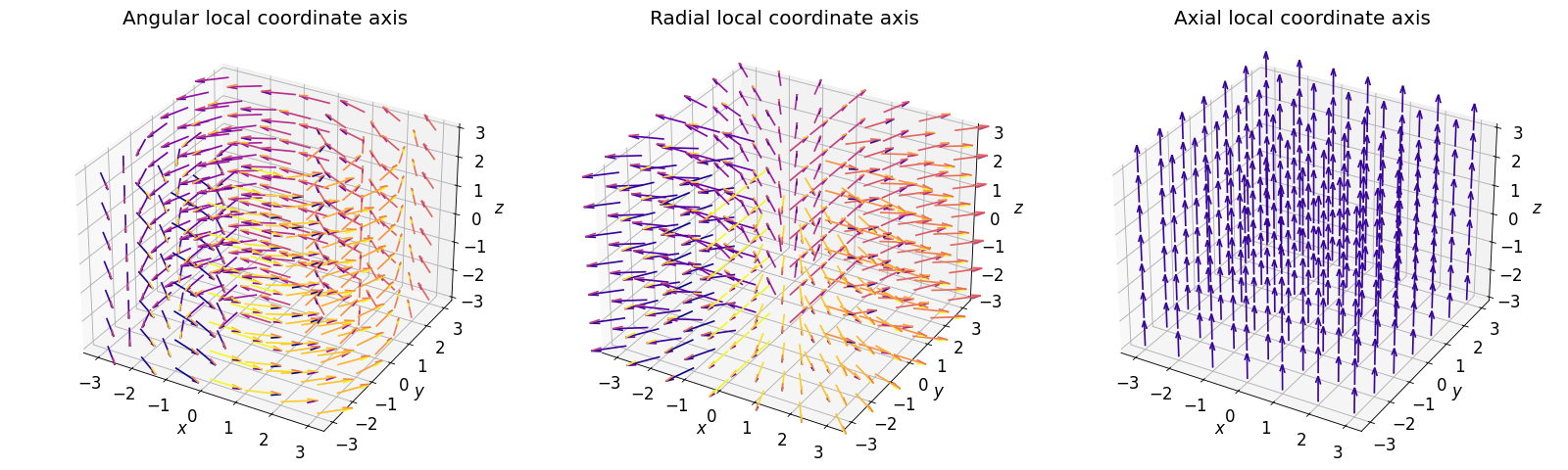
If only one of angular, radial, and axial is
True, the operator output has the same shape as the input, otherwise the gradients for the selected local coordinate axes are stacked on an additional axis at index 0.- Parameters:
axes (
Optional[Tuple[int,...]]) – Axes over which to compute the gradient. Should be a tuple \((i_x, i_y, i_z)\), where \(i_x\), \(i_y\) and \(i_z\) are input array axes assigned to \(x\), \(y\), and \(z\) coordinates respectively. Defaults toNone, in which case the axes are taken to be (0, 1, 2). If an integer, this operator returns ajax.Array. If a tuple orNone, the resulting arrays are stacked into aBlockArray.center (
Union[Tuple[int,...],Array,None]) – Center of the cylindrical coordinate system in array indexing coordinates. Default isNone, which places the center at the center of the two polar axes of the input array and at the zero index of the axial axis.angular (
bool) – Flag indicating whether to compute gradients in the angular (i.e. tangent to circles) direction.radial (
bool) – Flag indicating whether to compute gradients in the radial (i.e. directed outwards from the origin) direction.axial (
bool) – Flag indicating whether to compute gradients in the direction of the axis of the cylinder.cdiff (
bool) – IfTrue, estimate gradients using the second order central different returned bysnp.gradient, otherwise use the first order asymmetric difference returned bysnp.diff.input_dtype (
DType) – dtype for input argument. Default isfloat32.jit (
bool) – IfTrue, jit the evaluation, adjoint, and gram functions of the LinearOperator.
{kind=link}
{kind=link}
- class scico.linop.PolarGradient(input_shape, axes=None, center=None, angular=True, radial=True, cdiff=False, input_dtype=<class 'numpy.float32'>, jit=True)¶
Bases:
ProjectedGradientGradient projected into polar coordinates.
Compute gradients projected onto angular and/or radial axis directions, as described in [29]. Local coordinate axes are illustrated in the figure below.
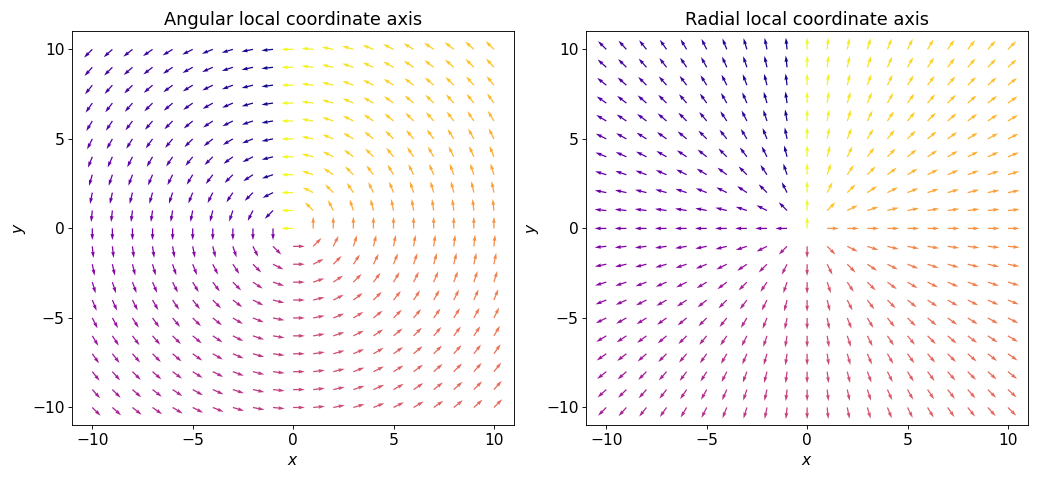
If only one of angular and radial is
True, the operator output has the same shape as the input, otherwise the gradients for the two local coordinate axes are stacked on an additional axis at index 0.- Parameters:
axes (
Optional[Tuple[int,...]]) – Axes over which to compute the gradient. Should be a tuple \((i_x, i_y)\), where \(i_x\) and \(i_y\) are input array axes assigned to \(x\) and \(y\) coordinates respectively. Defaults toNone, in which case the axes are taken to be (0, 1).center (
Union[Tuple[int,...],Array,None]) – Center of the polar coordinate system in array indexing coordinates. Default isNone, which places the center at the center of the input array.angular (
bool) – Flag indicating whether to compute gradients in the angular (i.e. tangent to circles) direction.radial (
bool) – Flag indicating whether to compute gradients in the radial (i.e. directed outwards from the origin) direction.cdiff (
bool) – IfTrue, estimate gradients using the second order central different returned bysnp.gradient, otherwise use the first order asymmetric difference returned bysnp.diff.input_dtype (
DType) – dtype for input argument. Default isfloat32.jit (
bool) – IfTrue, jit the evaluation, adjoint, and gram functions of the LinearOperator.
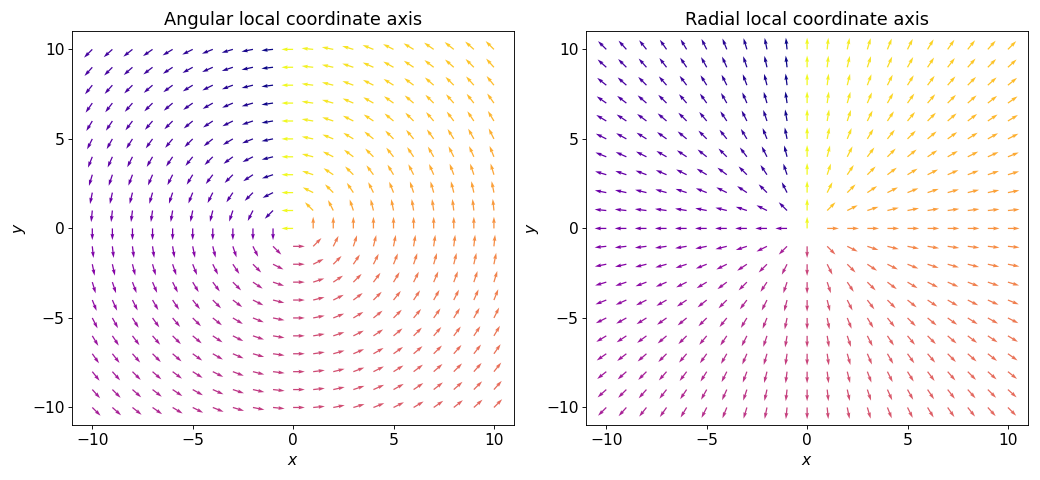{kind=link}
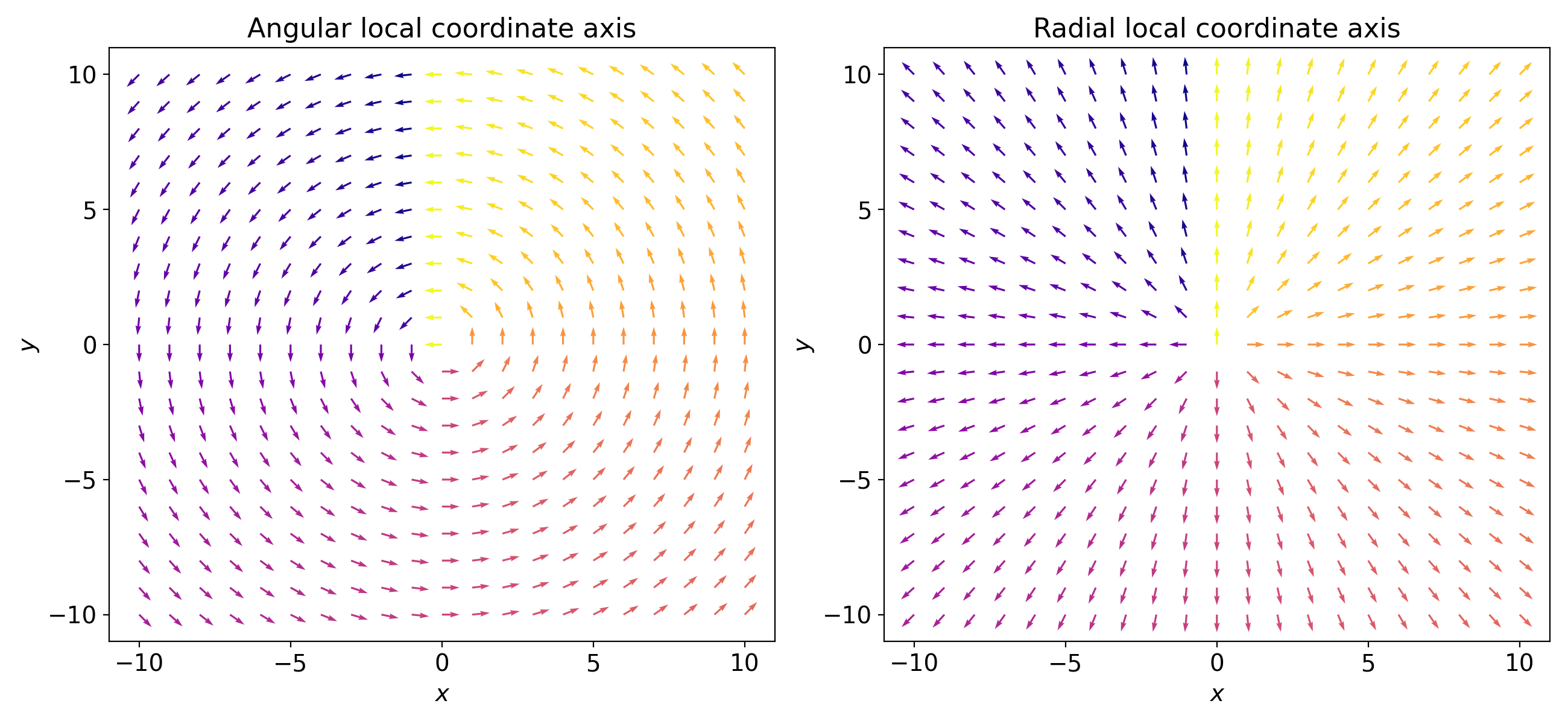{kind=link}
- class scico.linop.ProjectedGradient(input_shape, axes=None, coord=None, cdiff=False, input_dtype=<class 'numpy.float32'>, jit=True)¶
Bases:
LinearOperatorGradient projected onto local coordinate system.
This class represents a linear operator that computes gradients of arrays projected onto a local coordinate system that may differ at every position in the array, as described in [29]. In the 2D illustration below \(x\) and \(y\) represent the standard coordinate system defined by the array axes, \((g_x, g_y)\) is the gradient vector within that coordinate system, \(x'\) and \(y'\) are the local coordinate axes, and \((g_x', g_y')\) is the gradient vector within the local coordinate system.

Each of the local coordinate axes (e.g. \(x'\) and \(y'\) in the illustration above) is represented by a separate array in the coord tuple of arrays parameter of the class initializer.
Note
This operator should not be confused with the Projected Gradient optimization algorithm (a special case of Proximal Gradient), with which it is unrelated.
The result of applying the operator is always a
jax.Array. If coord is a singleton tuple, it has the same shape as the input array. Otherwise, the gradients for each of the local coordinate axes are stacked on an additional axis at index 0.If coord is
None, which is the default, gradients are computed in the standard axis-aligned coordinate system, and the shape of the returned array depends on the number of axes on which the gradient is calculated, as specified explicitly or implicitly via the axes parameter.- Parameters:
axes (
Optional[Tuple[int,...]]) – Axes over which to compute the gradient. Defaults toNone, in which case the gradient is computed along all axes.coord (
Optional[Sequence[Union[Array,BlockArray]]]) – A tuple of arrays, each of which specifies a local coordinate axis direction. Each member of the tuple should either be ajax.Arrayor aBlockArray. If it is the former, it should have shape \(N \times M_0 \times M_1 \times \ldots\), where \(N\) is the number of axes specified by parameter axes, and \(M_i\) is the size of the \(i^{\mrm{th}}\) axis. If it is the latter, it should consist of \(N\) blocks, each of which has a shape that is suitable for multiplication with an array of shape \(M_0 \times M_1 \times \ldots\).cdiff (
bool) – IfTrue, estimate gradients using the second order central different returned bysnp.gradient, otherwise use the first order asymmetric difference returned bysnp.diff.input_dtype (
DType) – dtype for input argument. Default isfloat32.jit (
bool) – IfTrue, jit the evaluation, adjoint, and gram functions of the LinearOperator.
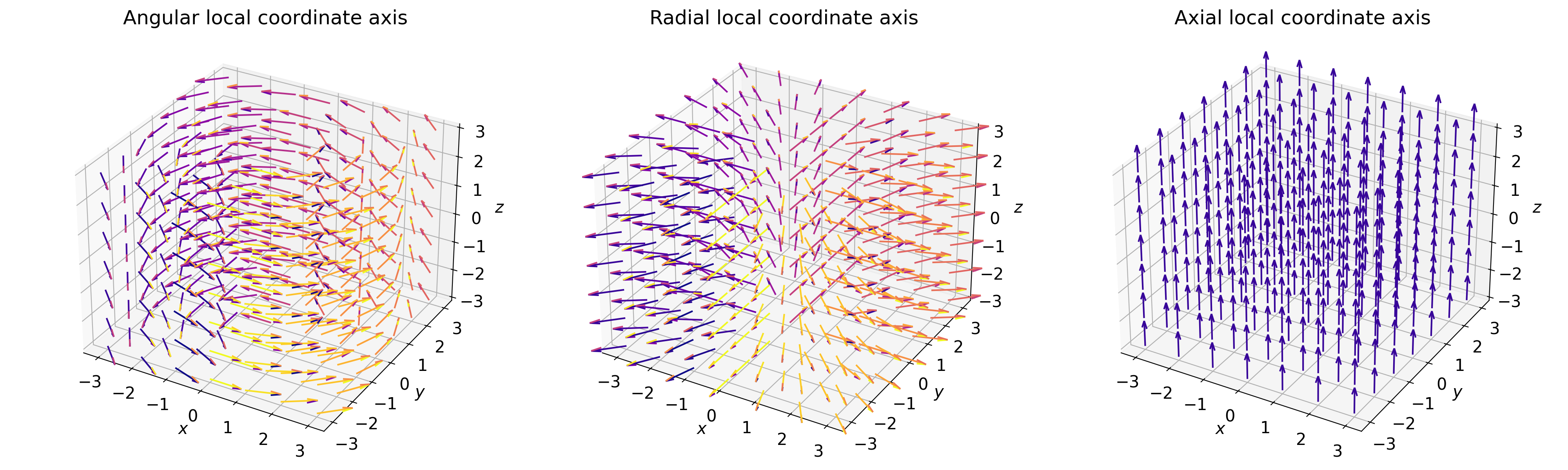
- class scico.linop.SphericalGradient(input_shape, axes=None, center=None, azimuthal=True, polar=True, radial=True, cdiff=False, input_dtype=<class 'numpy.float32'>, jit=True)¶
Bases:
ProjectedGradientGradient projected into spherical coordinates.
Compute gradients projected onto spherical coordinate axes, based on the approach described in [29]. The local coordinate axes are illustrated in the figure below.
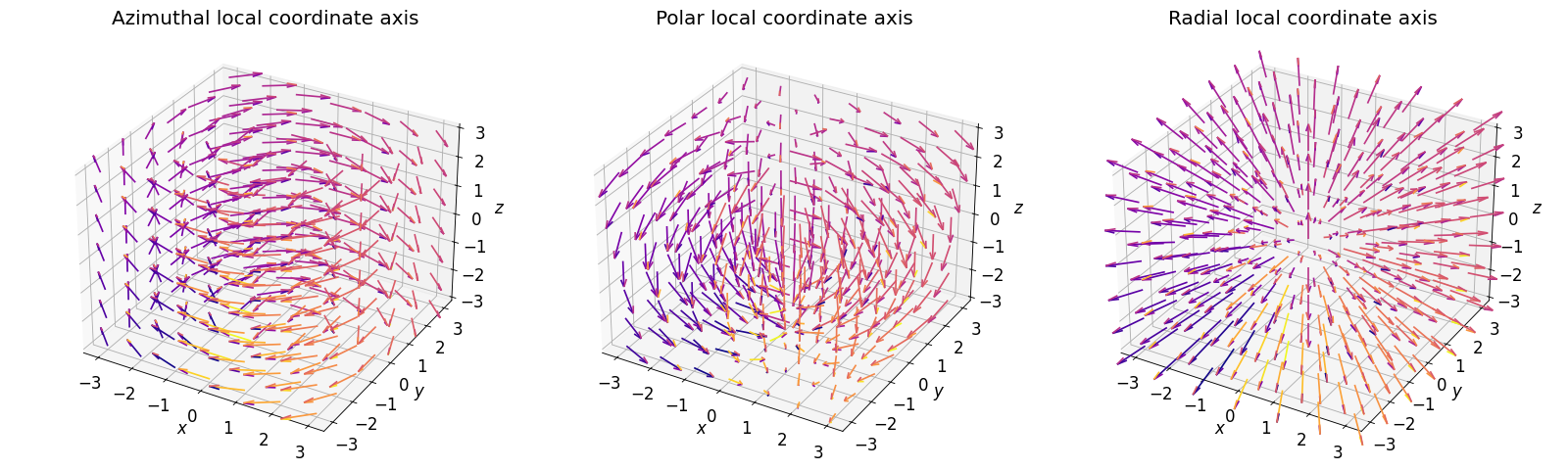
If only one of azimuthal, polar, and radial is
True, the operator output has the same shape as the input, otherwise the gradients for the selected local coordinate axes are stacked on an additional axis at index 0.- Parameters:
axes (
Optional[Tuple[int,...]]) – Axes over which to compute the gradient. Should be a tuple \((i_x, i_y, i_z)\), where \(i_x\), \(i_y\) and \(i_z\) are input array axes assigned to \(x\), \(y\), and \(z\) coordinates respectively. Defaults toNone, in which case the axes are taken to be (0, 1, 2). If an integer, this operator returns ajax.Array. If a tuple orNone, the resulting arrays are stacked into aBlockArray.center (
Union[Tuple[int,...],Array,None]) – Center of the spherical coordinate system in array indexing coordinates. Default isNone, which places the center at the center of the input array.azimuthal (
bool) – Flag indicating whether to compute gradients in the azimuthal direction.polar (
bool) – Flag indicating whether to compute gradients in the polar direction.radial (
bool) – Flag indicating whether to compute gradients in the radial direction.cdiff (
bool) – IfTrue, estimate gradients using the second order central different returned bysnp.gradient, otherwise use the first order asymmetric difference returned bysnp.diff.input_dtype (
DType) – dtype for input argument. Default isfloat32.jit (
bool) – IfTrue, jit the evaluation, adjoint, and gram functions of the LinearOperator.
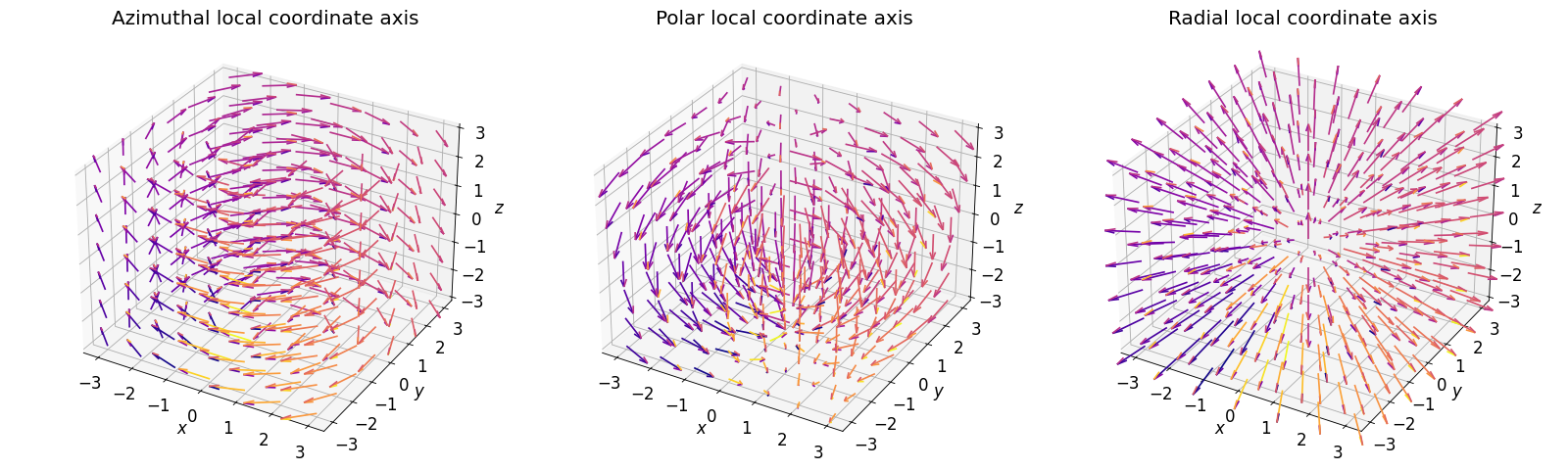{kind=link}
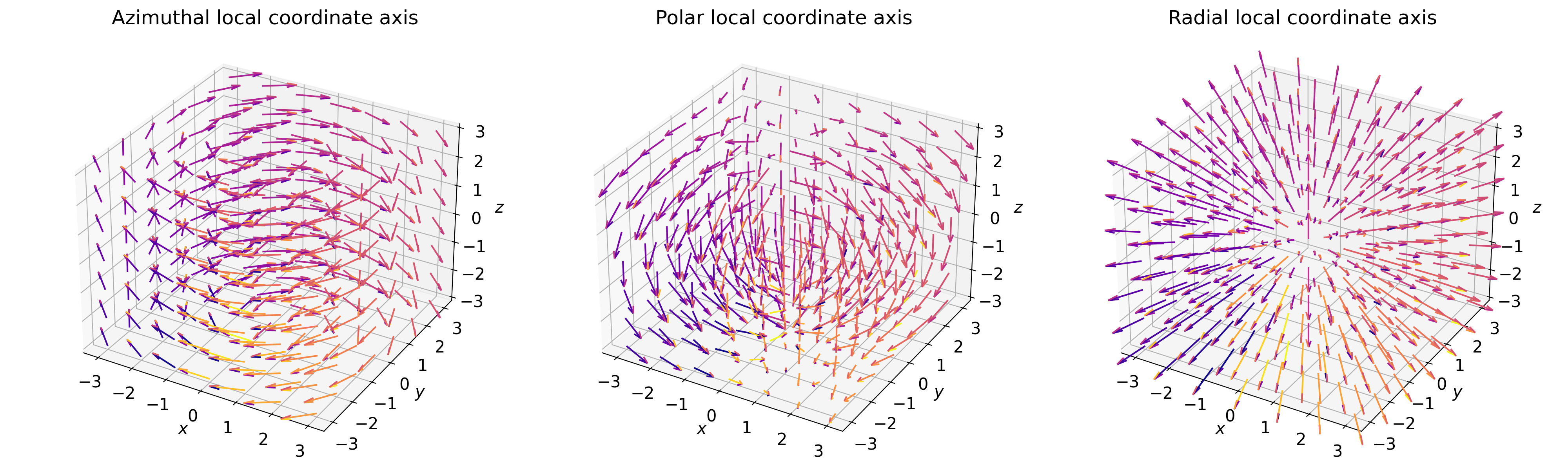{kind=link}
- class scico.linop.ComposedLinearOperator(A, B, jit=False)¶
Bases:
LinearOperatorA composition of two
LinearOperatorobjects.A new
LinearOperatorformed by the composition of two otherLinearOperatorobjects.A
ComposedLinearOperatorAB implements AB @ x == A @ B @ x.LinearOperatorA and B are stored as attributes of theComposedLinearOperator.LinearOperatorA and B must have compatible shapes and dtypes: A.input_shape == B.output_shape and A.input_dtype == B.input_dtype.- Parameters:
A (
LinearOperator) – First (left)LinearOperator.B (
LinearOperator) – Second (right)LinearOperator.jit (
bool) – IfTrue, calljiton thisLinearOperatorto jit the forward, adjoint, and gram functions. Same as callingjitafter theLinearOperatoris created.
- class scico.linop.LinearOperator(input_shape, output_shape=None, eval_fn=None, adj_fn=None, input_dtype=<class 'numpy.float32'>, output_dtype=None, jit=False)¶
Bases:
OperatorGeneric linear operator base class
- Parameters:
input_shape (
Union[Tuple[int,...],Tuple[Tuple[int,...],...]]) – Shape of input array.output_shape (
Union[Tuple[int,...],Tuple[Tuple[int,...],...],None]) – Shape of output array. Defaults toNone. IfNone, output_shape is determined by evaluating self.__call__ on an input array of zeros.eval_fn (
Optional[Callable]) – Function used in evaluating thisLinearOperator. Defaults toNone. IfNone, then self.__call__ must be defined in any derived classes.adj_fn (
Optional[Callable]) – Function used to evaluate the adjoint of thisLinearOperator. Defaults toNone. IfNone, the adjoint is not set, and the_set_adjointwill be called silently at the firstadjcall or can be called manually.input_dtype (
DType) – dtype for input argument. Defaults tofloat32. If theLinearOperatorimplements complex-valued operations, this must be a complex dtype (typicallycomplex64) for correct adjoint and gradient calculation.output_dtype (
Optional[DType]) – dtype for output argument. Defaults toNone. IfNone, output_dtype is determined by evaluating self.__call__ on an input array of zeros.jit (
bool) – IfTrue, calljiton thisLinearOperatorto jit the forward, adjoint, and gram functions. Same as callingjitafter theLinearOperatoris created.
- property H: LinearOperator¶
Hermitian transpose of this
LinearOperator.Return a new
LinearOperatorthat is the Hermitian transpose of thisLinearOperator. For a real-valuedLinearOperatorA (A.input_dtype isfloat32orfloat64), theLinearOperatorA.H is equivalent to A.T. For a complex-valuedLinearOperatorA (A.input_dtype iscomplex64orcomplex128), theLinearOperatorA.H implements the adjoint of A : A.H @ y == A.adj(y) == A.conj().T @ y).For the non-conjugate transpose, see
T.
- property T: LinearOperator¶
Transpose of this
LinearOperator.Return a new
LinearOperatorthat implements the transpose of thisLinearOperator. For a real-valuedLinearOperatorA (A.input_dtype isfloat32orfloat64), theLinearOperatorA.T implements the adjoint: A.T(y) == A.adj(y). For a complex-valuedLinearOperatorA (A.input_dtype iscomplex64orcomplex128), theLinearOperatorA.T is not the adjoint. For the conjugate transpose, use .conj().T orH.
- __call__(x)[source]¶
Evaluate this
LinearOperatorat the point \(\mb{x}\).- Parameters:
x (
Union[LinearOperator,Array,BlockArray]) – Point at which to evaluate thisLinearOperator. If x is ajax.ArrayorBlockArray, must have shape == self.input_shape. If x is aLinearOperator, must have x.output_shape == self.input_shape.- Return type:
Union[LinearOperator,Array,BlockArray]
- adj(y)[source]¶
Adjoint of this
LinearOperator.Compute the adjoint of this
LinearOperatorapplied to input y.- Parameters:
y (
Union[LinearOperator,Array,BlockArray]) – Point at which to compute adjoint. If y isjax.ArrayorBlockArray, must have shape == self.output_shape. If y is aLinearOperator, must have y.output_shape == self.output_shape.- Return type:
Union[LinearOperator,Array,BlockArray]- Returns:
Adjoint evaluated at y.
- conj()[source]¶
Complex conjugate of this
LinearOperator.Return a new
LinearOperatorAc such that Ac(x) = conj(A)(x).- Return type:
- gram(x)[source]¶
Compute A.adj(A(x)).
- Parameters:
x (
Union[LinearOperator,Array,BlockArray]) – Point at which to evaluate the gram operator. If x is ajax.ArrayorBlockArray, must have shape == self.input_shape. If x is aLinearOperator, must have x.output_shape == self.input_shape.- Return type:
Union[LinearOperator,Array,BlockArray]- Returns:
Result of A.adj(A(x)).
- property gram_op: LinearOperator¶
Gram operator of this
LinearOperator.Return a new
LinearOperatorG such that G(x) = A.adj(A(x))).
- class scico.linop.MatrixOperator(A, input_cols=0)¶
Bases:
LinearOperatorLinear operator implementing matrix multiplication.
- Parameters:
A (
Union[Array,ndarray,bool,number,bool,int,float,complex]) – Dense array. The action of the createdLinearOperatorwill implement matrix multiplication with A.input_cols (
int) – If this parameter is set to the default of 0, theMatrixOperatortakes a vector (one-dimensional array) input. If the input is intended to be a matrix (two-dimensional array), this parameter should specify number of columns in the matrix.
- property H¶
Hermitian (conjugate) transpose of this
MatrixOperator.Return a
MatrixOperatorcorresponding to the Hermitian (conjugate) transpose of this matrix.
- property T¶
Transpose of this
MatrixOperator.Return a
MatrixOperatorcorresponding to the transpose of this matrix.
- __call__(other)[source]¶
Evaluate this
LinearOperatorat the point \(\mb{x}\).- Parameters:
x – Point at which to evaluate this
LinearOperator. If x is ajax.ArrayorBlockArray, must have shape == self.input_shape. If x is aLinearOperator, must have x.output_shape == self.input_shape.
- adj(y)[source]¶
Adjoint of this
LinearOperator.Compute the adjoint of this
LinearOperatorapplied to input y.- Parameters:
y – Point at which to compute adjoint. If y is
jax.ArrayorBlockArray, must have shape == self.output_shape. If y is aLinearOperator, must have y.output_shape == self.output_shape.- Returns:
Adjoint evaluated at y.
- conj()[source]¶
Complex conjugate of this
MatrixOperator.Return a
MatrixOperatorwith complex conjugated elements.
- gram(other)[source]¶
Compute A.adj(A(x)).
- Parameters:
x – Point at which to evaluate the gram operator. If x is a
jax.ArrayorBlockArray, must have shape == self.input_shape. If x is aLinearOperator, must have x.output_shape == self.input_shape.- Returns:
Result of A.adj(A(x)).
- property gram_op¶
Gram operator of this
MatrixOperator.Return a new
LinearOperatorG such that G(x) = A.adj(A(x))).
- norm(ord=None, axis=None, keepdims=False)[source]¶
Compute the norm of the dense matrix self.A.
Call
scico.numpy.linalg.normon the dense matrix self.A.
- to_array()[source]¶
Return a
numpy.ndarraycontaining self.A.
- class scico.linop.DiagonalReplicated(op, replicates, input_axis=0, output_axis=None, map_type='auto', **kwargs)¶
Bases:
DiagonalReplicated,LinearOperatorA diagonal stack constructed from a single linear operator.
Given linear operator \(A\), create the linear operator
\[\begin{split}H = \begin{pmatrix} A & 0 & \ldots & 0\\ 0 & A & \ldots & 0\\ \vdots & \vdots & \ddots & \vdots\\ 0 & 0 & \ldots & A \\ \end{pmatrix} \qquad \text{such that} \qquad H \begin{pmatrix} \mb{x}_1 \\ \mb{x}_2 \\ \vdots \\ \mb{x}_N \\ \end{pmatrix} = \begin{pmatrix} A(\mb{x}_1) \\ A(\mb{x}_2) \\ \vdots \\ A(\mb{x}_N) \\ \end{pmatrix} \;.\end{split}\]The application of \(A\) to each component \(\mb{x}_k\) is computed using
jax.pmaporjax.vmap. The input shape for linear operator \(A\) should exclude the array axis on which \(A\) is replicated to form \(H\). For example, if \(A\) has input shape (3, 4) and \(H\) is constructed to replicate on axis 0 with 2 replicates, the input shape of \(H\) will be (2, 3, 4).Linear operators taking
BlockArrayinput are not supported.- Parameters:
op (
LinearOperator) – Linear operator to replicate.replicates (
int) – Number of replicates of op.input_axis (
int) – Input axis over which op should be replicated.output_axis (
Optional[int]) – Index of replication axis in output array. IfNone, the input replication axis is used.map_type (
str) – If “pmap” or “vmap”, apply replicated mapping usingjax.pmaporjax.vmaprespectively. If “auto”, usejax.pmapif sufficient devices are available for the number of replicates, otherwise usejax.vmap.
- class scico.linop.DiagonalStack(ops, collapse_input=True, collapse_output=True, jit=True, **kwargs)¶
Bases:
DiagonalStack,LinearOperatorA diagonal stack of linear operators.
Given linear operators \(A_1, A_2, \dots, A_N\), create the linear operator
\[\begin{split}H = \begin{pmatrix} A_1 & 0 & \ldots & 0\\ 0 & A_2 & \ldots & 0\\ \vdots & \vdots & \ddots & \vdots\\ 0 & 0 & \ldots & A_N \\ \end{pmatrix} \qquad \text{such that} \qquad H \begin{pmatrix} \mb{x}_1 \\ \mb{x}_2 \\ \vdots \\ \mb{x}_N \\ \end{pmatrix} = \begin{pmatrix} A_1(\mb{x}_1) \\ A_2(\mb{x}_2) \\ \vdots \\ A_N(\mb{x}_N) \\ \end{pmatrix} \;.\end{split}\]By default, if the inputs \(\mb{x}_1, \mb{x}_2, \dots, \mb{x}_N\) all have the same (possibly nested) shape, S, this operator will work on the stack, i.e., have an input shape of (N, *S). If the inputs have distinct shapes, S1, S2, …, SN, this operator will work on the block concatenation, i.e., have an input shape of (S1, S2, …, SN). The same holds for the output shape.
- Parameters:
ops (
Sequence[LinearOperator]) – Operators to stack.collapse_input (
Optional[bool]) – IfTrue, inputs are expected to be stacked along the first dimension when possible.collapse_output (
Optional[bool]) – IfTrue, the output will be stacked along the first dimension when possible.jit (
bool) – See jit inLinearOperator.
- class scico.linop.VerticalStack(ops, collapse_output=True, jit=True, **kwargs)¶
Bases:
VerticalStack,LinearOperatorA vertical stack of linear operators.
Given linear operators \(A_1, A_2, \dots, A_N\), create the linear operator
\[\begin{split}H = \begin{pmatrix} A_1 \\ A_2 \\ \vdots \\ A_N \\ \end{pmatrix} \qquad \text{such that} \qquad H \mb{x} = \begin{pmatrix} A_1(\mb{x}) \\ A_2(\mb{x}) \\ \vdots \\ A_N(\mb{x}) \\ \end{pmatrix} \;.\end{split}\]- Parameters:
ops (
Sequence[LinearOperator]) – Linear operators to stack.collapse_output (
Optional[bool]) – IfTrueand the output would be aBlockArraywith shape ((m, n, …), (m, n, …), …), the output is instead ajax.Arraywith shape (S, m, n, …) where S is the length of ops.jit (
bool) – See jit inLinearOperator.
- scico.linop.linop_over_axes(linop, input_shape, *args, axes=None, **kwargs)¶
Construct a list of
LinearOperatorby iterating over axes.Construct a list of
LinearOperatorby iterating over a specified sequence of axes, passing each value in sequence to the axis keyword argument of theLinearOperatorinitializer.- Parameters:
linop (
type[LinearOperator]) – Type ofLinearOperatorto construct for each axis.*args (
Any) – Positional arguments for theLinearOperatorinitializer.axes (
Union[int,Tuple[int,...],List[int],None]) – Axis or axes over which to construct the list. If not specified, orNone, use all axes corresponding to input_shape.**kwargs (
Any) – Keyword arguments for theLinearOperatorinitializer.
- Return type:
- Returns:
A tuple (axes, ops) where axes is a tuple of the axes used to construct the list of
LinearOperator, and ops is the list itself.
- scico.linop.jacobian(F, u, include_eval=False)¶
Construct Jacobian linear operator for a general operator.
For a specified
Operator, construct a corresponding JacobianLinearOperator, the application of which is equivalent to multiplication by the Jacobian of theOperatorat a specified input value.The implementation of this function is based on
Operator.jvpandOperator.vjp, which are themselves based onjax.jvpandjax.vjp. For reasons of computational efficiency, these functions return the value of theOperatorevaluated at the specified point in addition to the requested Jacobian-vector product. If the include_eval parameter of this function isTrue, the constructedLinearOperatorreturns aBlockArrayoutput, the first component of which is the result of theOperatorevaluation, and the second component of which is the requested Jacobian-vector product. If include_eval isFalse, then theOperatorevaluation computed byjax.jvpandjax.vjpare discarded.- Parameters:
F (
Operator) –Operatorof which the Jacobian is to be computed.u (
Array) – Input value of theOperatorat which the Jacobian is to be computed.include_eval (
Optional[bool]) – Flag indicating whether the result of evaluating theOperatorshould be included (as the first component of aBlockArray) in the output of the JacobianLinearOperatorconstructed by this function.
- Return type:
- Returns:
A
LinearOperatorcapable of computing Jacobian-vector products.
- scico.linop.operator_norm(A, maxiter=100, key=None)¶
Estimate the norm of a
LinearOperator.Estimate the operator norm induced by the \(\ell_2\) vector norm, i.e. for
LinearOperator\(A\),\[\begin{split}\| A \|_2 &= \max \{ \| A \mb{x} \|_2 \, : \, \| \mb{x} \|_2 \leq 1 \} \\ &= \sqrt{ \lambda_{ \mathrm{max} }( A^H A ) } = \sigma_{\mathrm{max}}(A) \;,\end{split}\]where \(\lambda_{\mathrm{max}}(B)\) and \(\sigma_{\mathrm{max}}(B)\) respectively denote the largest eigenvalue of \(B\) and the largest singular value of \(B\). The value is estimated via power iteration, using
power_iteration, to estimate \(\lambda_{\mathrm{max}}(A^H A)\).- Parameters:
A (
LinearOperator) –LinearOperatorfor which operator norm is desired.maxiter (
int) – Maximum number of power iterations to use. Default: 100key (
Optional[Array]) – Jax PRNG key. Defaults toNone, in which case a new key is created.
- Returns:
float – Norm of operator \(A\).
- scico.linop.power_iteration(A, maxiter=100, key=None)¶
Compute largest eigenvalue of a diagonalizable
LinearOperator.Compute largest eigenvalue of a diagonalizable
LinearOperatorusing power iteration.- Parameters:
A (
LinearOperator) –LinearOperatorused for computation. Must be diagonalizable.maxiter (
int) – Maximum number of power iterations to use.key (
Optional[Array]) – Jax PRNG key. Defaults toNone, in which case a new key is created.
- Returns:
tuple –
A tuple (mu, v) containing:
mu: Estimate of largest eigenvalue of A.
v: Eigenvector of A with eigenvalue mu.
- scico.linop.valid_adjoint(A, AT, eps=1e-07, x=None, y=None, key=None)¶
Check whether
LinearOperatorAT is the adjoint of A.Check whether
LinearOperator\(\mathsf{AT}\) is the adjoint of \(\mathsf{A}\). The test exploits the identity\[\mathbf{y}^T (A \mathbf{x}) = (\mathbf{y}^T A) \mathbf{x} = (A^T \mathbf{y})^T \mathbf{x}\]by computing \(\mathbf{u} = \mathsf{A}(\mathbf{x})\) and \(\mathbf{v} = \mathsf{AT}(\mathbf{y})\) for random \(\mathbf{x}\) and \(\mathbf{y}\) and confirming that
\[\frac{| \mathbf{y}^T \mathbf{u} - \mathbf{v}^T \mathbf{x} |} {\max \left\{ | \mathbf{y}^T \mathbf{u} |, | \mathbf{v}^T \mathbf{x} | \right\}} < \epsilon \;.\]If \(\mathsf{A}\) is a complex operator (with a complex input_dtype) then the test checks whether \(\mathsf{AT}\) is the Hermitian conjugate of \(\mathsf{A}\), with a test as above, but with all the \((\cdot)^T\) replaced with \((\cdot)^H\).
- Parameters:
A (
LinearOperator) – PrimaryLinearOperator.AT (
LinearOperator) – AdjointLinearOperator.eps (
Optional[float]) – Error threshold for validation of \(\mathsf{AT}\) as adjoint of \(\mathsf{AT}\). IfNone, the relative error is returned instead of a boolean value.x (
Optional[Array]) – If not the defaultNone, use the specified array instead of a random array as test vector \(\mb{x}\). If specified, the array must have shape A.input_shape.y (
Optional[Array]) – If not the defaultNone, use the specified array instead of a random array as test vector \(\mb{y}\). If specified, the array must have shape AT.input_shape.key (
Optional[Array]) – Jax PRNG key. Defaults toNone, in which case a new key is created.
- Return type:
- Returns:
Boolean value indicating whether validation passed, or relative error of test, depending on type of parameter eps.